第 4 章 查询语言
4.1 数据模型与查询语言
要设计一个数据库系统,第一步就是设计其对外的接口——外界要如何操作数据库中的数据,如何查找数据?
要解决这个问题,首先要定义一种数据模型。
数据模型主要包括两个部分:其一,其定义了数据在数据库中的逻辑表示,其二,其定义了外界操作数据的法则。
数据模型的意义在于,通过定义一套数据模型,我们可以用指定的语言描述我们想要的数据,剩下的工作就全部可以交给数据库系统进行,而不用我们关心。
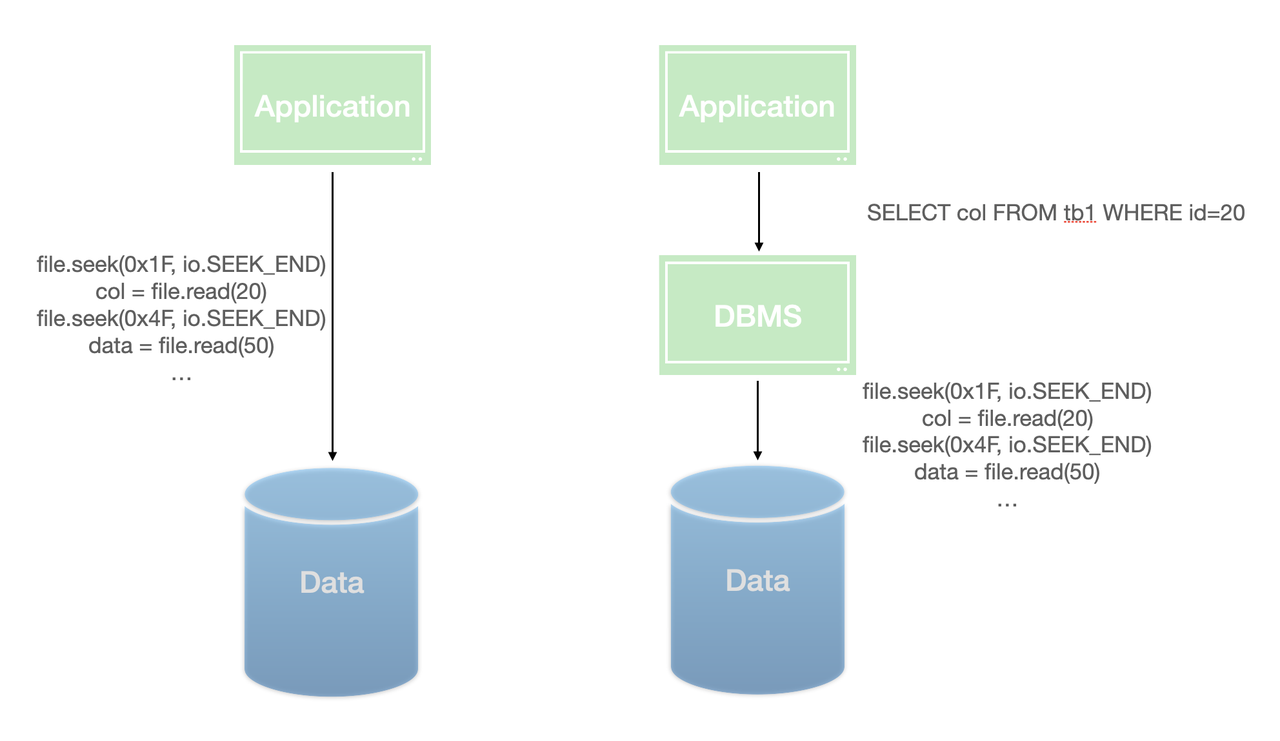
图 4.1: 查询语言
历史上,有非常多的数据模型,在此,我简单介绍几种。
4.1.1 层次(Hierarchical model)模型
在层次模型里,数据是通过类似树的形式组织的。
IBM 的 IMS 最先使用的是层级模型,IBM 为之开发了一种独特的数据查询语言,名为 DL/I (Data Language/One)。 下面是几个 DL/I 的例子:
GET CUSTOMERS BY NAME = 'SMITH'
GIVE ADDRESS PHONE在这里,GET 是 DL/I 的关键词,它表示要从 CUSTOMERS 这一数据集中获取数据。
BY 在这里也是一个关键词,表示要使用的筛选条件,最后,GIVE 关键词表示返回的数据中仅需要 ADDRESS 和 PHONE 这两个字段。
上面这个例子还不能很好地说明数据的层次结构,下面这个例子能够更好地说明这一点:
考虑你需要获取所有状态为 PENDING 的订单号和它对应的顾客姓名,你可以使用下面的语句:
GET ORDERS BY STATUS = 'PENDING'
GIVE ORDER-ID CUSTOMER-NAME通过上面两个例子,你应该可以发现,在 DL/I 中,数据是按照一棵树的形式展开的,ORDERS 表的结构大致如下:
ORDERS
ORDER-ID (integer)
CUSTOMER-NAME (string)
STATUS (string)而 CUSTOMER 则是上文中我们提到的另一个表:
CUSTOMERS
NAME (string)
ADDRESS (string)
PHONE (string)尽管在查询时通过这种方式来处理一对多关系非常便利,但由于其表示多对多关系时存在困难,且维护记录与记录的关系十分麻烦(记录与记录之间通过类似指针的方式关联,因此在更新时需要考虑非常多的内容),这种数据模型在70年代后逐渐被关系模型和 SQL 取代。
4.1.2 关系模型
关系模型是非常重要的模型,时至今日,关系模型及其衍生物 SQL 依然非常流行。
关系模型最初是在 A relational model of data for large shared data banks 这篇论文中由 IBM研究院 在 70 年代提出的,一个数据模型具有如此长久的生命力是非常不可思议的,恰恰说明了关系模型真的解决了之前的诸多问题。
在这篇文章中,作者首先指出了当时存在的层次模型与网络模型的诸多缺点,并提出了关系模型希望取而代之。有兴趣的读者可以进行阅读。上述模型的最重要缺陷之一是由于其对用户暴露了过多数据存储的细节(指针),进而引入了极大的编程复杂性,因此,关系模型在设计之初的核心思想就是这是一个声明式的模型,不会把关于数据存储的详细信息暴露给用户。
关系模型中,定义了 关系(relations) 和对 关系 的一系列 操作(operations) ,这些简单的操作可以叠加,从而形成复杂的关系表达能力。 3 个基本的关系操作是:
- 选择操作,可以选择关系中符合对应条件的记录。例如,以下表达式可以选择
Employees中所有Salary大于 50000 的记录。
σ Salary > 50000 (Employees)- 投影操作: 投影操作可以从关系集合中选择一部分列。
例如,下面的表达式可以表示从
Employees数据集中选择记录的Name和Salary字段。
π Name, Salary (Employees)- 连接: 连接操作可以将 2 个关系集合并成一个,通过指定连接字段,可以将拥有相同连接字段值的关系联合起来。例如,下面的表达式可以将
Employees和Departments这 2 个关系通过DepartmentID连接起来。
Employees ⨝ DepartmentID = DepartmentID (Departments)4.1.3 文档模型
最后,在结束之前,再介绍一种随着 noSQL (Not Only SQL)发展普遍被使用的模型——文档模型。
在一个文档模型的数据库中,你可以认为是一个 数据库(bucket) 中保存了 n 个 JSON ,一个数据库是一个 JSON 的 桶(bucket) ,每个 JSON 就是一条记录。这些 JSON 之间不需要有相同的结构,对 JSON 的大小等都没有限制。
与文档模型相比,关系模型要求一切都被定义好,所有的关系都必须预先定义好自己的 schema(列和列的类型) ,如果没有预先定义,那么这个列就无法被搜索和单独访问。然而,随着计算机软件的发展,出现了一些并不适合预先定义好 schema 的数据,另外,文档模型由于是一个 非归一化(denormalized) 的模型,记录与记录之间不会互相依赖,只需要保证单个文档的准确性,也不需要支持传统关系型数据库那样多个表之间的事务保证,在分布式部署等方面具有原生的优势,通常更益于并行计算,能够获得更大的性能收益。
4.2 定义自己的简单类SQL语言
SQL,即 Structured Query Language ,具有比较强的表达能力,最早在1979年由 Oracle 推向商用数据库市场。 随着关系型数据库的流行, SQL 的影响力日渐庞大,几乎所有的关系型数据库,甚至部分 KV数据库 、 列数据库 也支持 SQL 或 SQL方言 作为数据查询语言和操作语言。
接下来,为了实现我们自己的数据库,我们也需要为我们的数据库选择一种用于操作数据和查询数据的语言。这里,我选择了一种简化的 SQL 语言。这篇文章主要介绍如何定义这种语言。
4.2.1 一点点的编译原理小知识
首先,不妨思考这个问题:如何定义一句 SQL 语句是否合理?如何设计我们自己的 SQL 语法?
一个答案是使用 BNF范式(巴科斯范式)。
在解析一句 SQL 语句是否合法时,主要包括以下三个步骤。
第一步,词法分析,这一步中,我们会把用户输入的 SQL 语句分为一个个的 token ,每个 token 都是 BNF 中定义的关键词。
第二步,语法分析,在这一步,我们分析 token 的排列规则是否符合预先设定的规则,也就是是否符合我们定义的 BNF范式 的要求。经过语法分析后,我们能得到一些结构化的数据,这些结构对应的就是 SQL 语句的解析结果。比较典型的结构体是 Parse Tree 或者 AST (抽象语法树)。
第三步,语义分析,这一步中我们要分析已经确定符合 BNF范式 的语句是否存在语义上的缺陷,例如,是否在字符串类型的字段中插入了数字,等等。
下面,我会给一些简单的例子来介绍上面的步骤,并最终给出我们的 SQL 语句 BNF 。
4.2.2 词法分析
例如,我们有这样一条 SQL 语句: SELECT name FROM students WHERE age > '18';
在 词法分析 阶段,我们将该语句分解为以下 token : SELECT , name , FROM , students , WHERE , age , > ,'18' , ;
相信你也明白所谓的 词法分析 的作用了,在这一步中,我们定义一系列规则,来明确在我们定义的语言中什么样的字符可以连接在一起构成一个 token ,什么样的字符自己就是一个 token ,而什么样的字符是非法的。
具体来说,怎么定义 token 呢?接下来是定义 token 的方法
4.2.3 语法分析
有了 词法分析 的结果,就可以在此基础上进行 语法分析 。语法分析 的目的是检查 token 连在一起后是不是能符合我们定义的语法 ,并解析生成 抽象语法树
4.2.3.1 BNF范式的例子
在根据 BNF范式 来解析用户输入时,通常先认为用户输入的内容都属于第一条 BNF范式 , 随后根据具体情况根据右边的表达式展开即可。
<select-statement> ::= SELECT <column-list> FROM <table-name> WHERE <MARK> <OP> <CONST>;
<column-list> ::= <column-name> | <column-name>, <column-list>
<column-name> ::= <MARK>
<table-name> ::= <MARK>
<MARK> ::= <letter> {<letter-or-digit>}
<CONST> ::= '<MARK>'
<OP> ::= < | = | > | <= | >= | !=
<letter> ::= a | b | c | ... | z | A | B | C | ... | Z
<letter-or-digit> ::= <letter> | <digit>
<digit> ::= 0 | 1 | 2 | ... | 9上面是一个很简单的 BNF 例子,这个例子可以解析上面给出的 SQL 语句
当然了,它也有不少不足,举例来说,上面我们给出的 BNF范式 只能解析含有一个 WHERE 条件的 SELECT 语句, BNF 是表现力很强的语言,我们可以稍作修改,让我们定义的 SELECT 语句支持任意多个 WHERE 条件:
<select-statement> ::= SELECT <column-list> FROM <table-name> WHERE <condition>
<column-list> ::= <column-name> | <column-list>, <column-name>
<column-name> ::= <MARK>
<table-name> ::= <MARK>
<condition> ::= <expression> | <condition> <logical-op> <expression>
<expression> ::= <MARK> <OP> <CONST>
<logical-op> ::= AND | OR
<OP> ::= "=" | "<" | ">" | "<=" | ">=" | "!="
<MARK> ::= <letter> {<letter-or-digit>}
<CONST> ::= '<string>'
<string> ::= {<letter-or-digit>}
<letter> ::= a | b | c | ... | z | A | B | C | ... | Z
<letter-or-digit> ::= <letter> | <digit>
<digit> ::= 0 | 1 | 2 | ... | 9上面的例子里给出了一个支持任意多个 WHERE 条件的 SELECT 语句的 BNF范式
在这篇文章中,我暂时不会给出 BNF范式 应该如何解读的例子,希望读者反复研读上面给出的 2 则例子,对 BNF范式 建立一个大概的印象和理解。
如果读者阅读 BNF范式 时发现很难完全理解 BNF范式 的意义,在下一篇文章中会有如何根据 BNF范式 编写程序、解析出 AST 的内容,可以参阅那部分的内容。
4.2.3.2 根据BNF范式来进行语法解析
仅仅给出 BNF范式 的方式,对没有编译原理基础的读者可能不友好,读者可能不知道应该如何利用 BNF范式 来解析语句,但在这节内容中,我们仅仅强调 BNF范式 定义的语法可以将用户输入的 SQL语句 解析为 AST。
下面,我们做一个将 SELECT 语句最后解析成 AST 的例子:
考虑下面的 SQL 语句:SELECT name FROM students WHERE age > '18' AND gender = 'M';
在完成基本的词法分析,将 SQL语句 转化成 token 后,就可以根据 BNF范式 得到以下的 抽象语法树 :
<select-statement>
├── <column-list>
│ └── <column-name>
│ └── name
├── <table-name>
│ └── students
└── <condition>
├── <expression>
│ ├── <MARK>
│ │ └── age
│ ├── <OP>
│ │ └── >
│ └── <CONST>
│ └── '18'
├── <logical-op>
│ └── AND
└── <expression>
├── <MARK>
│ └── gender
├── <OP>
│ └── =
└── <CONST>
└── 'M'读者可以发现,AST树 中的所有 叶子结点 都是 BNF范式 中定义的不可继续展开(称为终止符)的,而 AST树 的 根节点 则是第一条 BNF范式。
关于如何根据 BNF 来直接解析出上面这颗 AST 的算法,在本篇文章中暂时不涉及,会在之后的篇幅中给简单介绍。
4.3 实现一个简单SQL解析器
4.3.1 自顶向下的语法解析器
让我们回忆之前提到过的可以描述 SELECT 语句的 BNF范式 :
<select-statement> ::= SELECT <column-list> FROM <table-name> WHERE <MARK> <OP> <CONST>;
<column-list> ::= <column-name> | <column-name>, <column-list>
<column-name> ::= <MARK>
<table-name> ::= <MARK>
<MARK> ::= <letter> {<letter-or-digit>}
<CONST> ::= '<MARK>'
<OP> ::= < | = | > | <= | >= | !=
<letter> ::= a | b | c | ... | z | A | B | C | ... | Z
<letter-or-digit> ::= <letter> | <digit>
<digit> ::= 0 | 1 | 2 | ... | 9在这篇文章中,我会一步一步介绍如何使用自顶向下的解析方式来根据 BNF范式 解析这句 SQL :
4.3.2 BNF范式的基本概念
我们首先来回顾一下 BNF范式 ,以这条 BNF范式 为例:
在这句 BNF范式 的左侧,是一个名为 <select-statement> 的 非终止符
在 BNF范式 的右侧,是SELECT <column-list> FROM <table-name> WHERE <MARK> <OP> <CONST>;,这是一个 终止符 与 非终止符 混合的 展开式 。
其中,SELECT、FROM、WHERE、; 是 终止符 ,而 <column-list> <table-name> <MARK> <OP> <CONST> 是 非终止符 。
从这些描述中你可以发现,所谓的终止符就是常量,是不可以再向外推导的内容,而非终止符则有其他的 BNF范式 可以继续进行推导。
而在根据 BNF范式 推导用户输入生成 AST 时,我们总有一个起始的状态,在这里 <select-statement> 就是我们的起始状态。
4.3.3 根据BNF范式生成AST的过程
接下来,我以这句 SQL 为例,演示如何根据 BNF范式 、自顶向下的解析方法来生成 AST :
SELECT name FROM students WHERE age > '18';4.3.3.1 生成token
不难发现,在进行了简单的 词法分析 后,上面的 SQL 语句可以解析为下面的这些 token :
- SELECT
(name) - FROM
(students) - WHERE
- (age)
(>) (‘18’)
4.3.3.2 自顶向下解析
接下来,可以根据 BNF 进行解析,从最顶端的 非终止符 <select-statement>开始,尝试将输入的 token 匹配到这个 BNF范式 。
SELECT是 终止符 ,它与输入的第一个 token 匹配,因此消耗这个 token 。下一个是
<column-list>,由于 BNF范式 中存在<column-list> ::= <column-name> | <column-name>, <column-list>,它可以继续扩展为<column-name>,又可以继续展开为<MARK>。这里<MARK>可以进一步扩展为<letter> {<letter-or-digit>}。在这个例子中,name与这个模式匹配,所以消耗 tokenname。下一个 终止符 是
FROM,与输入的下一个 token 匹配,所以消耗 tokenFROM。接着是
<table-name>。我们的输入 token 是<letter-or-digit>(students),它可以匹配为<table-name>中的<MARK>。此时,students匹配<letter> {<letter-or-digit>},因此消耗 tokenstudents。接下来的 终止符
WHERE与输入的 token 匹配,所以消耗 tokenWHERE。下一个 非终止符 是
<MARK>,与输入的 token<MARK>(age)匹配,所以消耗 tokenage。下一个 终止符
<OP>与输入的 token<OP>(>)匹配,所以消耗 token>。最后,
<CONST>与输入的 token<CONST>('18')匹配,所以消耗token'18'。
以上,我们成功地使用 BNF范式 和 自顶向下的解析方法 ,将给定的 SQL 语句解析为一系列的 token ,并与 BNF范式 进行匹配。
4.3.3.3 生成AST(抽象语法树)
基于上述的解析过程,你可以发现,我们从第一条 BNF范式 出发,通过递归下降的方式直到我们将所有的 token 都推导为 终止符 ,而从这个推导的过程,我们可以构建一个简化的 AST :
<select-statement>
|
|-- SELECT
|
|-- <column-list>
| |
| |-- <column-name>
| |
| |-- name
|
|-- FROM
|
|-- <table-name>
| |
| |-- students
|
|-- WHERE
|
|-- <condition>
|
|-- <MARK>
| |
| |-- age
|
|-- <OP>
| |
| |-- >
|
|-- <CONST>
|
|-- '18'这样,通过自顶向下的解析方法和 BNF范式 ,我们将一个 SELECT 语句转化为了 AST ,方便之后的 语义分析 和 代码生成。
4.3.3.4 用Python实现自顶向下解析Demo
上述的过程已经很容易理解,但为了进一步明确,我把解析的过程用 python 代码实现了一下。有需要的读者可以把代码和上面的解析过程进行对照:
class Node:
def __init__(self, value):
self.value = value
self.children = []
def add_child(self, child):
self.children.append(child)
def __repr__(self, level=0):
ret = "\t" * level + repr(self.value) + "\n"
for child in self.children:
ret += child.__repr__(level + 1)
return ret
def parse(tokens):
current_token_index = 0
def consume(expected):
nonlocal current_token_index
if tokens[current_token_index] == expected:
current_token_index += 1
return True
return False
def parse_mark():
nonlocal current_token_index
node = Node(tokens[current_token_index])
current_token_index += 1
return node
def parse_op():
nonlocal current_token_index
node = Node(tokens[current_token_index])
current_token_index += 1
return node
def parse_const():
nonlocal current_token_index
node = Node(tokens[current_token_index])
current_token_index += 1
return node
def parse_column_list():
node = Node('column-list')
while True:
node.add_child(parse_mark())
if not consume(','):
break
return node
def parse_table_name():
node = Node('table-name')
node.add_child(parse_mark())
return node
def parse_where():
node = Node('Where')
mark = Node('Mark')
mark.add_child(parse_mark())
op = Node('OP')
op.add_child(parse_op())
const = Node('Const')
const.add_child(parse_const())
node.add_child(mark)
node.add_child(op)
node.add_child(const)
return node
def parse_select_statement():
# 解析入口
root = Node('select-statement')
if not consume('SELECT'):
raise ValueError("Expected 'SELECT'")
root.add_child(parse_column_list())
if not consume('FROM'):
raise ValueError("Expected 'FROM'")
root.add_child(parse_table_name())
if not consume('WHERE'):
raise ValueError("Expected 'WHERE'")
root.add_child(parse_where())
return root
return parse_select_statement()
# 已经分好的token
tokens = ['SELECT', 'name', 'FROM', 'students', 'WHERE', 'age', '>', "'18'"]
# 自顶向下解析
ast = parse(tokens)
print(ast)上面的 python 代码完全复现了之前描述的自顶向下解析过程,根据 词法分析 的结果解析出了一颗 抽象语法树 ,下面是运行的结果: