第 5 章 存储基础
5.1 硬盘与操作系统
大家都知道数据是存储在硬盘上的,这篇文章会重点讨论硬盘与操作系统是如何交互的,这部分的讨论侧重于软件的讨论,硬盘还有一些值得注意的硬件特性,例如高延迟、随机读写性能差、读写放大等特性,会在另外的文章中讨论。
5.1.1 操作系统如何认识硬盘
目前,硬盘已经有多种不同的物理接口,消费级硬件中主流的是 SATA 和 NGFF (M.2) 接口的硬盘,SATA 接口的硬盘几乎一定默认使用 AHCI 协议与操作系统进行交互,而 NGFF 接口的硬盘可能会存在支持 AHCI 和 NVMe 两种不同协议的硬盘,彼此之间不互相兼容。
本文要讨论的是操作系统与硬件交互的标准方式,也就是类似软件上接口(interface)的概念,因此本文主要讨论的是AHCI或者NVMe,而不是SATA或者NGFF。
5.1.2 操作系统对硬盘的抽象
以 AHCI 协议为例,AHCI 协议是 Intel 牵头制定的,官方有详细的协议规范: https://www.intel.com/content/www/us/en/io/serial-ata/serial-ata-ahci-spec-rev1-3-1.html
这份规范是非常底层的,直接说明了操作系统与硬件如何交互:

图 5.1: 规范中对数据FIS传输的说明
抽象来说,AHCI 包括了一些命令,操作系统可以通过操作内存来调用这些命令,下面是我抽象的几个指令:
| 指令 | 作用 |
|---|---|
| Read Sector | 用来读取一个或者多个扇区的数据 |
| Write Sector | 用来写入一个或者多个扇区的数据 |
| Identify Device | 获取设备描述信息 |
| Flush Cache | 强制硬盘将缓存中的数据写入到盘上 |
| Standby Immediate | 提示硬盘从待机状态恢复到工作状态 |
| Idle Immediate | 提示硬盘从工作状态切换到低功耗待机模式 |
| Data Set Management | 用来提示硬盘进行TRIM等操作(SSD和Host managed SMR盘常用) |
| Read FPDMA Queued | 将一个读取指令加入到硬盘本地的队列中,硬盘可以乱序执行队列中的指令来获得最佳性能 |
| Write FPDMA Queued | 将一个写入指令加入到硬盘本地的队列中,硬盘可以乱序执行队列中的指令来获得最佳性能 |
其中的很多指令都很容易理解,例如Read Sector,就是读取数据的指令,Idle Immediate 是对硬盘电源状态进行管理的指令,我想,读者可能会对Data Set Management 这一指令的作用有些困惑,这里就对这个做一下展开解释。
SSD 和 Host-Managed SMR 硬盘有一个特性:在写入数据前必须先擦除掉这部分的数据,而擦除需要花费不少时间。因此,操作系统可以通过这些指令在文件删除时就通知 SSD:这片区域不再使用了,SSD 就会在空闲时进行擦除操作,节省下次写入时需要的时间。这种操作可以认为是一种垃圾回收过程,不过需要注意其与内存管理中的垃圾回收有明显区别。
除了对 AHCI 的底层命令进行抽象封装外,操作系统还进行了一系列额外的工作,这部分工作视操作系统的不同而不同。例如,在 Linux 系统中,所有的硬盘都被抽象为块设备:
# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
sda 8:0 0 20G 0 disk
├─sda1 8:1 0 476M 0 part /boot
└─sda2 8:2 0 19.5G 0 part /通过上面的命令可以看出,在这台系统上有 20G 的硬盘,这块硬盘分为 2 个分区,被 Linux 系统识别为sda的块设备。
下一节,我们简单聊一聊 Linux 系统中的“块设备”的特性和使用方法。
5.1.3 块设备(Block device)
为什么 Linux 系统将硬盘抽象成块设备?块设备是什么含义?
块设备在 Linux 系统上是指能够按照固定大小的块进行数据存取的设备,例如,对于扇区大小是 512B 的硬盘来说,块的大小就是 512B ,在 Linux 系统上,下面所有的设备都是块设备:
| 设备名称 | 设备类型 |
|---|---|
| /dev/sdX | AHCI设备 |
| /dev/sr0 | 光驱 |
| /dev/hdX | IDE设备 |
| /dev/nvmeX | NVMe设备 |
| /dev/mmcblkX | MMC设备(eMMC或者SD卡) |
在 Unix 系统中,一切都是文件,因此,块设备作为文件也实现了文件的基本接口,可以被标准的文件 API 读取和写入:
# sudo head -c 8 /dev/sda
?c??м# 以上的命令使用 head 工具读取了硬盘最开始的 8 个字节的数据,当然了,展示出来的是乱码,因为这些二进制数据不是用 ASCII 编码的。
5.2 机械硬盘特性与文件缓存
在上一节,我们聊了硬盘与系统交互的标准接口,但没有涉及到硬盘的硬件特性。在这一节,我们简单讨论一下硬盘的一些基本硬件特性,以及操作系统对这些硬件特性所做的优化工作。
5.2.1 最小读写单位
磁盘在经过操作系统的封装后,对用户来说有和内存几乎相同的读写方式。就像内存是一个大数组一样,磁盘本身也被“块” (Block) 这一概念分割,对于磁盘来说,一个“块”的大小通常是 512B (机械硬盘和大部分 SSD )~4K (少量新款 SSD 系统),在访问磁盘数据的时候,也是通过 Offset 的方式来访问,你告诉硬盘需要第 4 页(从 0 开始),那么硬盘就会把第 2048~2560Byte 的数据给你。
硬盘的块大小可以通过smartctl工具获得
# smartctl -a /dev/nvme0n1
smartctl 7.2 2020-12-30 r5155 [x86_64-linux-5.15.0-58-generic] (local build)
Copyright (C) 2002-20, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Number: INTEL SSDPEKKF010T8L
Serial Number: PHHH843401491P0E
Firmware Version: L08P
PCI Vendor/Subsystem ID: 0x8086
IEEE OUI Identifier: 0x5cd2e4
Controller ID: 1
NVMe Version: 1.3
Number of Namespaces: 1
Namespace 1 Size/Capacity: 1,024,209,543,168 [1.02 TB]
Namespace 1 Formatted LBA Size: 512
Namespace 1 IEEE EUI-64: 5cd2e4 2591417dab
Local Time is: Wed Jan 25 07:44:23 2023 UTC
Firmware Updates (0x14): 2 Slots, no Reset required
Optional Admin Commands (0x0017): Security Format Frmw_DL Self_Test
Optional NVM Commands (0x005f): Comp Wr_Unc DS_Mngmt Wr_Zero Sav/Sel_Feat Timestmp
Log Page Attributes (0x0f): S/H_per_NS Cmd_Eff_Lg Ext_Get_Lg Telmtry_Lg
Maximum Data Transfer Size: 64 Pages
Warning Comp. Temp. Threshold: 75 Celsius
Critical Comp. Temp. Threshold: 80 Celsius
...可以看到,这块硬盘的块大小是 512 Byte。
这样的地址在OS中称为 LBA (Logical Block Address) ,当然,实际 上LBA 之所以是 Logical Address 的是因为他并不像内存那样具备实际意义。 在机械硬盘上,LBA 会被硬盘转换为 CHS 格式 (第C磁盘第H柱面第S扇区,我从网上找了一张示意图) ,在现代的 SSD 上,LBA 与闪存的 Block 或者 Page 亦无固定的对应关系,是在运行时由硬盘的固件动态分配的。
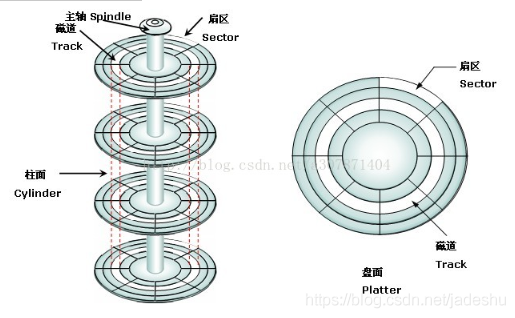
图 5.2: CHS与扇区的对应关系
5.2.2 分区
人们为了 提高机械硬盘的性能 , 会把硬盘分为多个区。外圈的硬盘速度比内圈慢,而扇区号从小到大对应的是从硬盘的外圈到硬盘的内圈,因此系统装在开始的分区能够获得更好的性能 。(在 SSD 上,分区对性能没有什么帮助)
所谓分区就像我们在一个分区内创建了一个个文件一样,也是在一块连续空间上由元数据记录、划分的一块块空间,在以前,分区表的格式叫 MBR ,由于 MBR 是 90 年代的产物,存在诸多如最大分区大小的限制,后续由 GPT 取代。关于 MBR 和 GPT 并没有太多与我们相关的细节需要了解,我们只需要知道这些是规定了分区起始位置和结束为止的元数据即可。如果你对这块内容有更多兴趣,可以参阅:MBR与GPT
5.2.3 使用整个分区作为数据库文件的好处
说了这么多,终于可以聊一些和数据库有关的话题了。
在 Oracle 数据库中,用户是可以选择一整个分区给数据库使用的。为什么 Oracle 要用这种方式来管理数据,而不是单纯使用一个文件呢?要知道,文件比分区更容易保存、备份,倘若空间不够用,要给文件扩容时,也只需要把文件复制进一个更大的分区,而不是像分区一样来回调整分区表和修正分区数据。在维护便利性上,文件是比分区更好的,尽管如此,为什么 Oracle 还是提供了使用分区的选项呢?
答案很简单,因为 Oracle 想要排除 OS 的一切影响。
OS 提供的文件管理机制并不适合数据库使用,举例来说,大部分的 OS 都会对文件进行预读操作,但遗憾的是 OS 并不理解数据库的文件结构,按照简单的顺序预读也许只会造成资源的浪费。OS 为什么要进行预读操作呢?这与硬盘的特性息息相关,因为硬盘本身的访问速度慢,带宽低,而大部分对硬盘数据的读写都遵循数据局部性,也就是经常需要被一起访问的数据通常都存在相邻的地方。
5.2.4 Linux如何加速文件的读写
以 Linux 为例,简单介绍一下 OS 为了加速文件读写都会做些什么。
需要注意,下面的部分说法是不准确的,只能给你一个大概的蓝图,如果你对具体的细节更有兴趣,应该阅读其他拓展材料。
补充一个我记忆中的趣事,Windows 在 Windows XP 开始引入了一个名为 Prefetch 的服务,这个服务的作用是在启动程序前进行劫持动作,由 OS 判断程序是否经常读取某些文件,如果发现程序经常读取某些特定文件,就会在启动程序前尝试将特定文件加载到内存中,通过这种方式来加快程序之后的运行速度。
类似的机制在 Windows Vista 中进化为了一个名叫 SuperFetch 的服务,微软官方似乎并没有仔细介绍工作原理的文档,但可以肯定 Superfetch 比 Prefetch 用了更激进的、主动式的预读策略,以至于那个年代的 Windows 经常把用户2-4G的内存占满,引起了用户(特别是中国,因为某些特殊原因中国用户有看自己还剩多少内存的习惯)的强烈不满。
由于 Windows 的文档实在匮乏,我也不了解 Windows 的细节,上面的 Windows 的例子只是为了让读者对预读的重要性有一个基本的认知。接下来以 Linux 为例介绍 OS 对文件的预读操作。
在开始介绍之前,我会先罗列一些 Linux 缓存文件的基础概念。
原则上,除非在挂载文件系统时或者用户要求,所有的读写请求均会经过磁盘缓存
用户在写入文件时,文件会被先写进内存中,在内存中被称为 Dirty Page ,需要等待内核在内核认为合适的时机或者用户手动执行
fsync命令时同步到硬盘读取文件时也是同理,系统会首先判断当前要读取的部分在不在 Page Cache 中,如果命中就直接使用
Linux 系统根据局部性原理会对文件进行预读,并不是你请求哪些它就会读哪些到内存中
如果应用程序修改了文件的一个部分,这部分还在缓存中,那么要让缓存失效
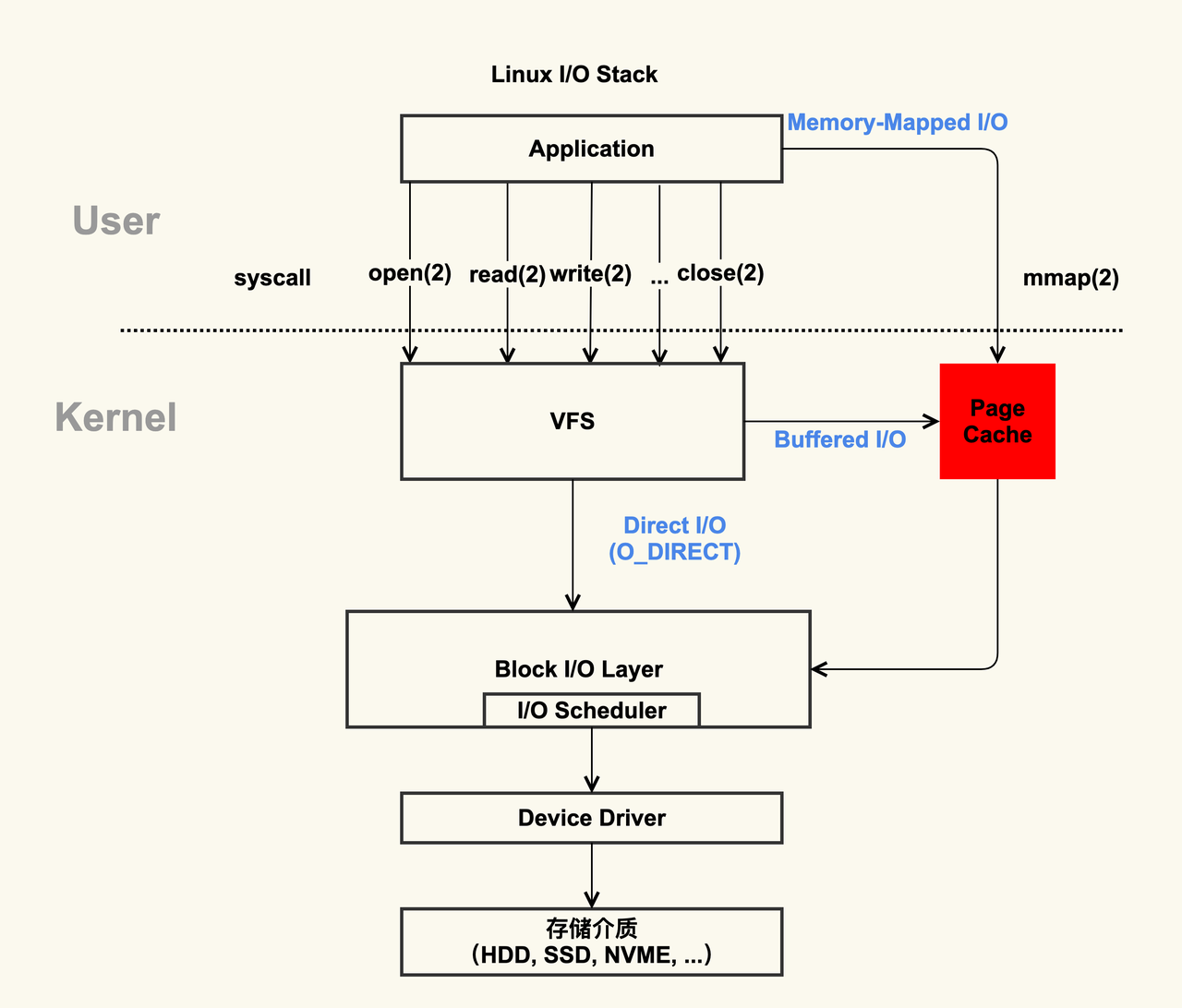
图 5.3: Linux 的 Page Cache
我觉得这篇文章以及这一系列的文章都写得不错,对IO有进一步了解兴趣的话可以去看
接下来,通过几个实验来验证 Linux 的文件预读和缓存机制
首先,我们准备一个 4G 内存的机器,和一个 8G 的文件,并保证这个文件不在系统的 Page Cache 中
# free -wh
total used free shared buffers cache available
Mem: 3.8Gi 192Mi 3.4Gi 716Ki 16Mi 203Mi 3.6Gi
Swap: 0B 0B 0B
# vmtouch -v testfile.img # 展示文件有多少在内存缓存中
testfile.img
[ ] 0/2048000
Files: 1
Directories: 0
Resident Pages: 0/2048000 0/7G 0%
Elapsed: 0.10211 seconds接下来,我们读取一下这个文件,这是第一次读取后的结果
# vmtouch -v testfile.img
testfile.img
[oooooooooooooooooooooooooooooooooooOOOOOOOOOOOOOOOOOOOOOOOOO] 911200/2048000
Files: 1
Directories: 0
Resident Pages: 911200/2048000 3G/7G 44.5%
Elapsed: 0.31019 seconds
# free -wh
total used free shared buffers cache available
Mem: 3.8Gi 189Mi 31Mi 716Ki 15Mi 3.6Gi 3.6Gi
Swap: 0B 0B 0B可以看到,随着文件的读取,系统只缓存了后半部分的内容,这是由于前半部分在内存中放不下了,被置换出去了。
因此,可以发现一个简单的道理,对于内存中存储不下的巨量文件,如果这个文件不满足局部性原理,缓存几乎是没有作用的。我们可以尝试着多读取几遍这个文件,看看性能有没有改善。
# time cat testfile.img > /dev/null
cat testfile.img > /dev/null 0.32s user 36.07s system 20% cpu 3:01.72 total
# time cat testfile.img > /dev/null
cat testfile.img > /dev/null 0.24s user 34.55s system 19% cpu 3:00.17 total
# time cat testfile.img > /dev/null
cat testfile.img > /dev/null 0.28s user 32.02s system 19% cpu 2:46.45 total可以看到,性能几乎没有改善。
这个问题在设计数据库时也是需要关注的,如果要利用操作系统的缓存,那么可能会同时访问的数据要放在相邻的位置上。
接下来,我们实验系统的文件预读功能,我会把 Page Cache 先全部清除,然后从文件中读取 120K 的文件,我们看看系统读取了多少数据到内存中。
# sysctl -w vm.drop_caches=3
vm.drop_caches = 3
# vmtouch -v testfile.img
testfile.img
[ ] 0/2048000
Files: 1
Directories: 0
Resident Pages: 0/2048000 0/7G 0%
Elapsed: 0.11164 seconds
# dd if=testfile.img of=/dev/null bs=1K count=120
120+0 records in
120+0 records out
122880 bytes (123 kB, 120 KiB) copied, 0.0074944 s, 16.4 MB/s
# vmtouch -v testfile.img
testfile.img
[o ] 92/2048000
Files: 1
Directories: 0
Resident Pages: 92/2048000 368K/7G 0.00449%
Elapsed: 0.13552 seconds可以看到,虽然我们只读取了 120K 的数据,但系统把文件开头的 368K 都读进了内存中。
5.2.5 O_DIRECT
有没有办法完全阻止操作系统来做这些文件的缓存操作呢?
如果你做了一些简单的搜索,你会发现网络上大量推崇使用 O_DIRECT 来绕过 Linux 系统的 Page Cache ,这并不一定正确。
O_DIRECT只是程序向系统许下的一个愿望,而非一个命令
在遇到这些需要明确系统行为的问题时,我鼓励读者阅读官方的文档,而不是阅读博客之类的二手知识。
open(2) - Linux manual page 这是官方 manual 中关于 O_DIRECT 的解释
O_DIRECT (since Linux 2.4.10) Try to minimize cache effects of the I/O to and from this file. In general this will degrade performance, but it is useful in special situations, such as when applications do their own caching. File I/O is done directly to/from user-space buffers. The O_DIRECT flag on its own makes an effort to transfer data synchronously, but does not give the guarantees of the O_SYNC flag that data and necessary metadata are transferred. To guarantee synchronous I/O, O_SYNC must be used in addition to O_DIRECT. See NOTES below for further discussion. A semantically similar (but deprecated) interface for block devices is described in raw(8).
可以看到,文档中说对于使用 O_DIRECT 这一 flag 打开的文件,系统只是会尽力保证不使用缓存,不能提供任何保证。同时还特别强调,如果要保证完成写入操作时文件已经写入到磁盘上,应该额外使用 O_SYNC 这一 flag。
那么 O_DIRECT 为什么只能提供尽力的保证呢?因为事实上最终的行为还依赖于 Linux 内核的版本、磁盘挂载时的选项、文件系统提供的支持等。
举例来说,某些文件系统(如 btrfs)在修改文件时并不会在原地进行修改,而是使用 Copy On Write 的方式来优化性能,这些实现细节都会影响最终提供的保证。总结来说,对于不直接使用分区而是使用文件的数据库来说,文件系统是一个极大的变数。例如在www.phoronix.com中,评测了不同文件系统对数据库性能的影响。
5.3 SSD特性与随机读写性能
在之前的一定篇幅中,简单介绍了机械硬盘的基本特性,这篇文章会补充介绍 SSD 的相关特性,另外还包括一个小实验,用于验证硬盘的性能,让读者对硬盘性能有进一步感性的认识。
很多人认为,由于有了 SSD ,数据库的性能相比机械硬盘就相差无几了,甚至认为,对 SSD 可以任意进行读写而不必考虑优化,诚然,SSD 相比机械硬盘的提升是指数级的,但这并不意味着 SSD 本身的特性上没有明显的问题和需要注意的地方。
在开始之前,我还要补充一个关于存储的基本知识。
什么是随机存储器,什么是非随机存储器呢?
其实,在这块并没有很明确的定义,随着闪存的普及,硬盘也可以在某种程度上认为是一个“随机访问存储器”,但我还是要指出,SSD 所使用的 NAND Flash 和 DRAM 为代表的“随机访问存储器”有着明显的区别。
我在这里明确定义:如果一个存储器,可以按照处理器的“字” (WORD) 为单位进行随机读写,那么它就是随机存储器,反之,它就不是。

图 5.4: 不同存储器最小读取大小的对比
根据上述定义,抛开 Optane 等新兴的非易失性内存不谈,我们的硬盘都是不支持随机访问的,不论是机械硬盘还是 SSD ,都不支持随机访问。用之前的文章中提到的概念来说,块设备都是不支持随机访问的。这是由它们的硬件特性决定的。
关于机械硬盘为什么随机性能很差,之前已经介绍过,这里补充介绍 SSD 的特性:
SSD 的底层使用的存储介质是 NAND Flash,NAND Flash 的最小读取单位是一个 Page ,而最小重编程单位更是达到了一个 Block ,这意味着,对 SSD 来说,每次最小读取一个 Page (越是新的 NAND Flash 页大小越大,10 年前 (2013) 的主流 Page Size 是 8K) ,而每次更新数据时的最小写入单位更是达到了一个 Block ,通常是 64~128 个 Page (随着闪存容量变大,这个值还会变大)。
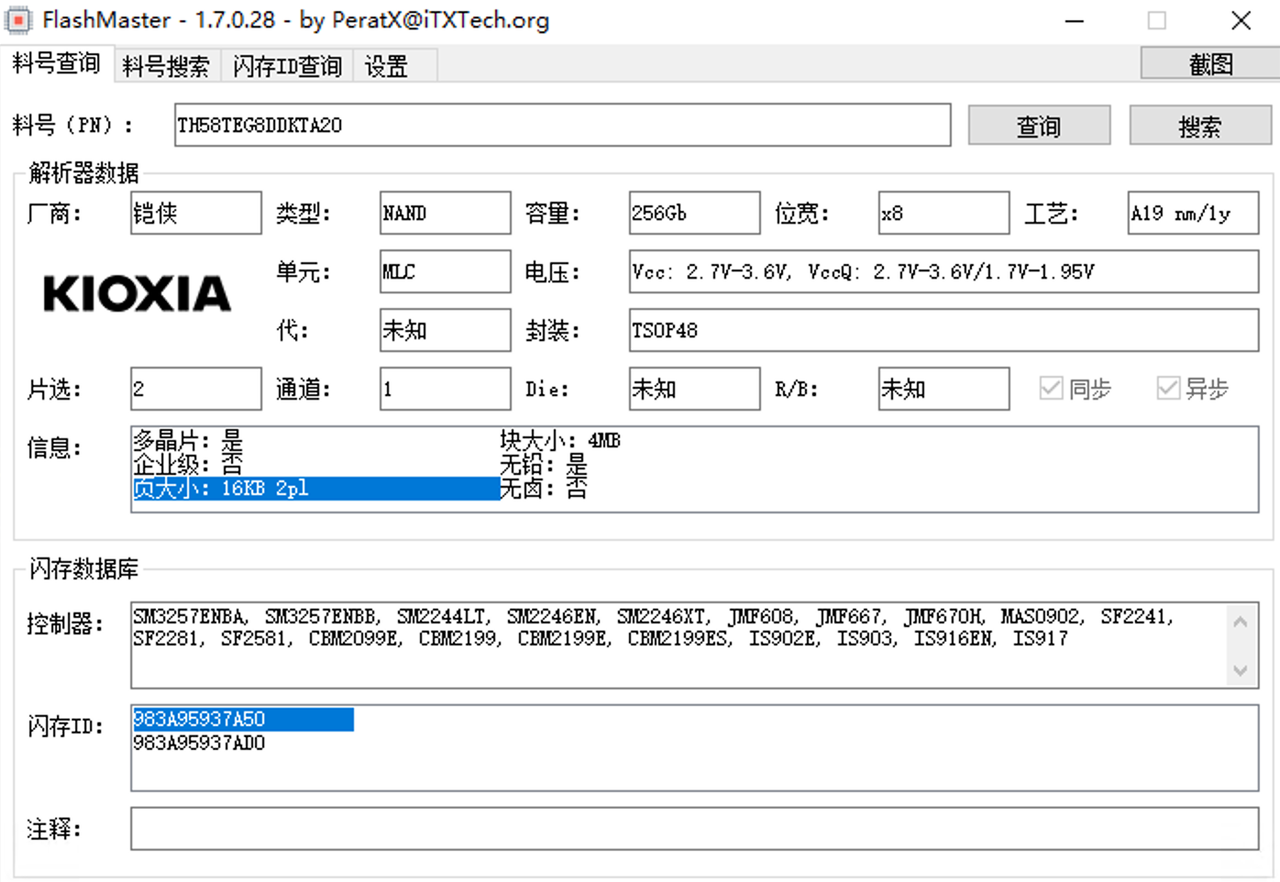
图 5.5: 2015年量产的TH58TEG8DDKTA20闪存的页大小已经高达16KB
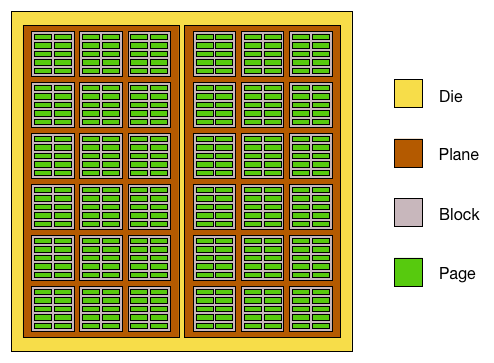
图 5.6: Nand Flash结构示意图,图源AnandTech
而,如果我们要随机读取大量的小文件,造成的读写放大都是巨大的。如果 SSD 每次最小读取 64KB ,而要读取的数据大小是 4K,那么就存在 16 倍的读取放大。
这里,我们可以简单写一个程序来测试硬盘的随机 4K 读取性能,可以看到,对于 OS 无法进行预读缓存的随机 4K 读取,即使是在 SSD 上也存在巨大的性能损耗。
import os
import random
class IOBenchmark:
def __init__(self):
self.RANDOM_FILE_NAME = "random_file.pytest"
def createRandomFile(self, sizeInMegaByte=1024):
with open(self.RANDOM_FILE_NAME, 'wb') as fout:
fout.write(
os.urandom(sizeInMegaByte * 1024 * 1024))
fout.flush()
os.fsync(fout)
def random4KRead(self, ioOperations = 30000):
import time
with open(self.RANDOM_FILE_NAME, 'rb') as fin:
t0 = time.time()
for i in range(ioOperations):
fin.seek(random.randint(0, os.stat(self.RANDOM_FILE_NAME).st_size))
fin.read(4096)
print("Performed {0} iops 4k random read in {1} seconds".format(ioOperations, time.time()-t0))
if __name__ == '__main__':
ioBench = IOBenchmark()
# ioBench.createRandomFile()
ioBench.random4KRead()仅仅是进行 30000 次随机的 io 读写,性能如何呢?这里我在 SATA 的固态硬盘上做了个简单测试
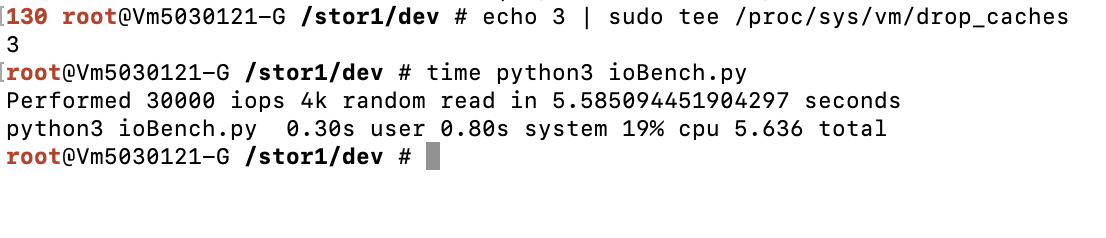
图 5.7: 30000次随机4k读取测试
可以看到,仅仅是 30000 次的随机读,就要花费 5.6秒 的时间。折算下来的读取速度大约是 20MB/S ,这符合 SATA SSD 的典型性能表现
除了介质本身存在如此大的读取放大损失外,设备本身的响应时间也十分慢。永远记住,假设 CPU 从 L1D 取数据的速度是 1 秒,那么 CPU 从 SSD 取数据的时间大约是 1 天。
5.4 文件系统
在之前的文章中,简单介绍了硬盘与操作系统交互的方式。读者现在应该已经认识到硬盘可以被抽象为一个“块设备”,并且对硬盘的硬件特性有了一些了解。但仅仅这样距离硬盘可以被用在实际使用中还有一些距离。举例来说,有下面这些关键的问题没有解决。
很显然,作为用户,我们不可能直接去操纵硬盘并记忆数据的地址。那么:
- 用户如何决定要将数据存储在哪里?
- 用户如何快速索引出之前存进硬盘里的数据?
为了解决这些问题,需要文件系统的支持。
文件系统决定了用户的数据在硬盘上的组织方式,不同的操作系统有不同的文件系统,比如,Windows 常用的文件系统是 NTFS ,Linux 系统比较常用的文件系统是 EXT4 。每个文件系统的特性都有不同,不同的文件系统适应不同的使用场景。下面我会简单介绍一下文件系统的基本常识。
5.4.1 FAT32简介
上文简单介绍了文件系统的概念,但可能没有办法帮助读者建立起具象的印象,因此,在这一小节我会选取一个简单的文件系统作为例子来讨论它是如何工作的。
这里,我直接引用 FAT32 文件系统的结构。FAT32 是微软在上世纪 90 年代推出的文件系统,在早期曾经作为 Windows XP 等系统的系统分区默认文件系统,但现在已经几乎完全淘汰,只有少数的可移动存储设备在使用 FAT32 文件系统,FAT32 是 FAT (File Allocation Table, 文件分配表) 文件系统的 32 位版本,是这一系列文件系统的最后版本,从这个文件系统的名字也可以看出来,这种文件系统相对是比较原始的,很适合用来举例子和学习。
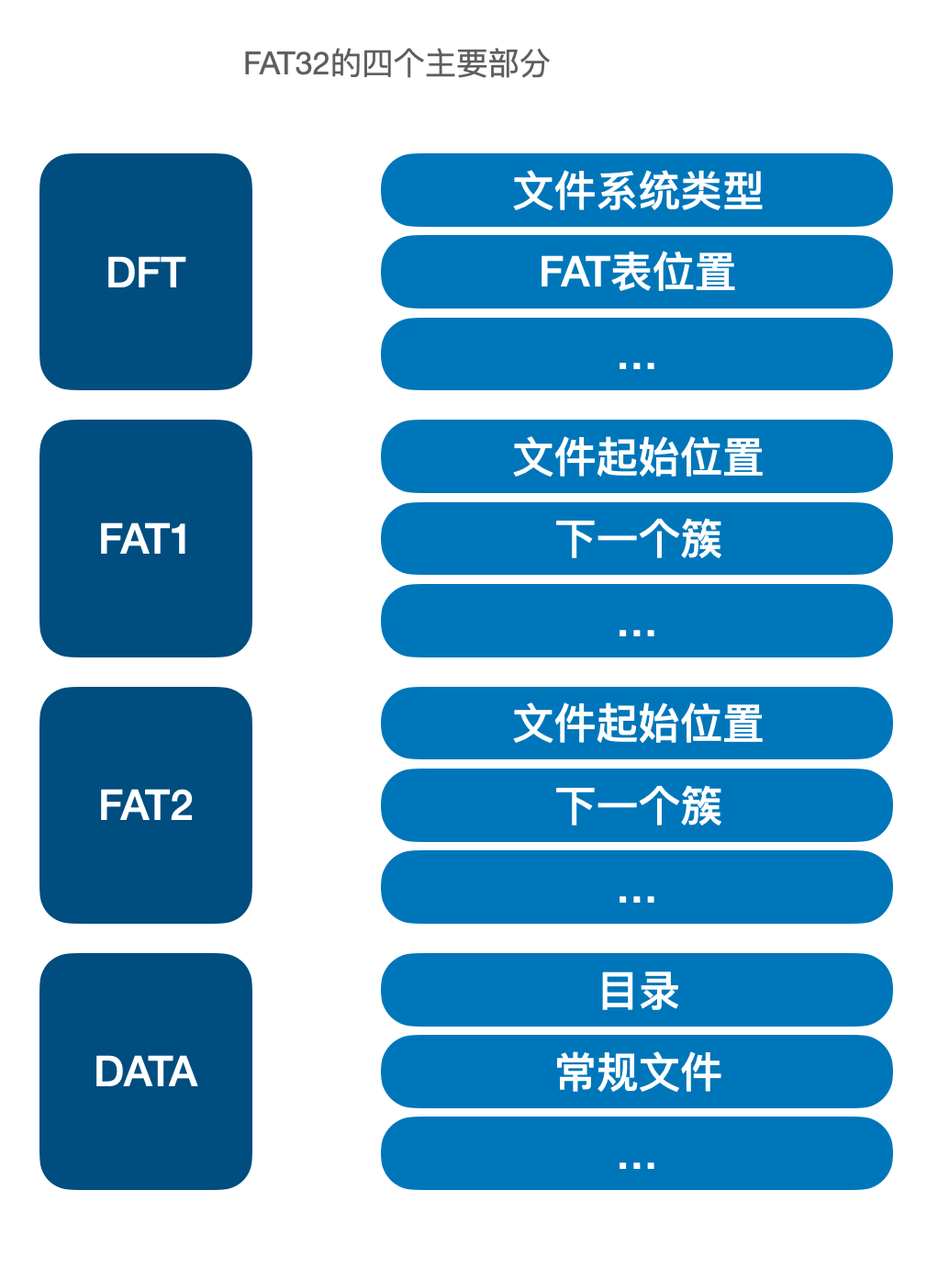
图 5.8: FAT32的四个主要部分和其作用
5.4.2 簇
在 FAT32 文件系统中,管理存储数据的最小单元是“簇”,一个簇的大小是扇区的 2^n 倍,举例来说,一个簇可以是 2个、4个、8个…64个 扇区。 FAT32 将最小管理单位定位可变的簇,主要原因是扇区这一硬盘的原始单位实在是太小,仅仅只有 512 个字节,如果使用扇区来作为文件系统中文件的地址直接使用,不仅会更多地占用文件分配表(文件分配表直接记录了文件的簇地址),还容易出现更多的文件碎片(即,一个文件被打散在多个不连续的簇上,影响读写性能)。根据簇的定义,一旦给定了某个文件系统的簇的尺寸,就可以根据簇的编号直接定位到簇所在的扇区。
5.4.3 FAT
FAT32 管理文件位置的工具被称为文件分配表(FAT),文件分配表是一段固定大小的空间,和数据区的簇的数量一一对应,有多少个簇,文件分配表中就有多少条记录。而每条记录在文件分配表中占 32 个比特,这也是 FAT32 这一名字的由来。
文件分配表的作用是用来在提示对应的簇上有没有文件,以及对应的簇存储的文件是在簇内就结束了,还是需要再读取下一个簇来读取下一部分。因此,文件分配表可能看起来像是这样:

图 5.9: FAT的簇链
5.4.4 目录管理
目录(文件夹)可能在一些读者眼中是一种相对特殊的概念,读者可能认为目录没有办法作为普通文件来管理。事实上,在 FAT32 中,目录和普通文件的管理方式完全一致,这也大大降低了文件系统的复杂度。
在 FAT32 文件系统中,目录也是一种特殊的文件,这种文件上记录着文件夹下对应有哪些文件和它们对应的簇,和其他文件一样,如果一个簇存不下所有的文件信息,那么就可以在 FAT 表新增一条记录接着记录。
5.4.5 FAT32的灾难恢复
FAT32 文件系统包括四个部分:DBR 、FAT1 、FAT2 和 数据区。其中,DBR 是一段固定大小的区域,这块区域主要记录用来加载文件系统所必需的信息,例如文件系统的类型、簇的大小、FAT 的起始位置等,有了这些信息,文件系统驱动才能准确地识别出文件系统。关于 DBR 和 FAT 的作用,之前已经说明,现在主要说明 FAT2 的作用,以及 FAT32 文件系统如何在崩溃中恢复:
FAT1 和 FAT2 是两份完全一样的文件分配表,之所以保留 2 份,是为了当出现 FAT1 损坏的时候可以用 FAT2 进行替换。FAT2 是 FAT32 恢复机制的一部分。
读者可能想到,FAT2 中的数据不一定是最新的,这也就意味着尽管文件系统可能会恢复,但是用户已经写入的文件有可能会丢失,已经删除的文件也可能又出现。为了避免这一问题,有对应的被称为 chkdsk 的工具。这一工具会对 FAT32 全盘进行扫描,而不是依赖 FAT 来进行文件的发现。当它扫描到实际存在但在 FAT 中不存在的文件时,就会将它们添加到 FAT 中,以前的操作系统里在分区的根目录通常会有 LOSTFOUND.000 的目录,这一目录的作用就是存储 chkdsk 扫描全盘发现的文件。这就是 FAT32 的崩溃恢复过程。