第 3 章 DBMS简介
3.1 数据库系统发展简史
在 1960 年代,计算机刚被发明不久,当时计算机远没有普及,软件生态相较今天也十分简单。但在当时,就已经有大型公司尝试着使用计算机来管理数据了。
使用计算机来管理数据有很多好处,相较于传统的纸质数据管理方式,计算机一次性能够记录更多的数据,在数据的检索和管理上也更为容易,存在数据更不容易丢失等优势。
1960 年代主要的数据库系统是以 IDS 为代表的层级数据库。这么说可能会让读者没有概念,因此,为了描述数据库系统,我首先展开一下数据库系统的几个基本概念。
3.1.1 数据模型
所有的数据存储都依赖一个事先定义好的数据模型。以大家熟悉的 MySQL 举例,MySQL 是一种关系型数据库管理系统 (Relational DBMS) 。 MySQL 的数据模型是基于关系代数建立的,在 MySQL 中,所有的数据都从属于一个“表”,这个“表”可以与其他“表”进行关系代数运算。这就是一种非常典型的数据模型。
3.1.1.1 层级数据库
最早期的数据库大部分都是层级数据库 (Hierarchical Database),在层级数据库中,所有的数据都是按照层级组织的。通常来说,这种类型的数据库中都有一个根结点,当用户需要寻找什么数据的时候,需要手动操作数据库,从根结点出发,定位到自己想要的数据。
举例来说,如果要存储书和作者的关系,可能看起来是下面这样:
RECORD Author
AuthorID: INTEGER
Name: STRING
Birthdate: DATE
Books: SET OF Book
RECORD Book
BookID: INTEGER
Title: STRING
PublicationDate: DATE
Author: REFERENCE TO Author
// 定义作者
AUTHOR_1 = Author(AuthorID=1, Name="J.K. Rowling", Birthdate="31/07/1965")
AUTHOR_2 = Author(AuthorID=2, Name="George Orwell", Birthdate="25/06/1903")
// 定义书
BOOK_1 = Book(BookID=1, Title="Harry Potter and the Sorcerer's Stone", PublicationDate="26/06/1997", Author=AUTHOR_1)
BOOK_2 = Book(BookID=2, Title="1984", PublicationDate="08/06/1949", Author=AUTHOR_2)
// 通过这种方式将作者和书链接起来
AUTHOR_1.Books = [BOOK_1]
AUTHOR_2.Books = [BOOK_2]
// 查询的例子
// 找到所有AUTHOR_1写的书
for book in AUTHOR_1.Books:
print(book.Title)
// 获取BOOK_2的作者名
print(BOOK_2.Author.Name)可以看到,在这种数据模型下,用户需要手动跟踪数据中存储的指针,直到找到自己的数据位置
1960 年代时,主要的数据库就是这种形式。这种形式的数据库中查询数据很复杂,和关系型数据库相比,不仅不能一次性使用外键连接多个表,而且查询数据的方式主要依赖代码实现,很难让用户单独使用命令查询。
在 1970 年代,随着关系代数的论文被发表,关系型数据库的概念开始兴起。我们今天所熟悉的 SQL 也被发明了。 IBM 的 System R 是第一个实现了关系代数模型的数据库产品。不过,由于当时的计算机尚未普及,对数据库系统系统的需求基本还停留在大型公司,其他大部分公司没有对数据库产品的需求。但 1970 年代的意义是重大的,因为关系型数据库这一时至今日仍然流行的数据模型就是在那时被确立的。
当然,尽管有了关系型数据库的雏形,当时的数据库系统还有很多基础研究没有完成。举例来说,对于数据库系统应该如何处理并发请求,如何管理锁来避免用户数据出现问题,直到 1990 年代才有系统性的论文出现。
随着计算机和互联网的普及,数据库系统不再是单纯的为大公司服务的昂贵系统,举例来说,1995 年微软发布了 Microsoft SQL Server ,这是一款能够运行在普通个人计算机上的数据库管理系统,而随着互联网的发展,越来越多的网站被建立起来,对数据库系统的需求激增,因此,以 MySQL 、MsSQL 、Postgres 等为代表的可以运行在普通个人计算机上的数据库系统从 1990 年代开始流行。
3.2 数据库系统的模块
不论数据库系统有哪些功能、实现哪种数据模型,在一些地方始终是相通的。本文介绍数据库系统通常的架构是什么样的。
我们来考虑一个基本的数据库系统,它至少包含以下两个部分:
用来处理用户请求的部分
用来管理数据存储的部分
通常,第一个部分被称为数据库系统的前端,而第二个部分被称为数据库系统的后端。
接下来, 我们分别考察这两个部分。
3.2.1 数据库的前端
3.2.1.1 查询解析器
这部分需要解析用户输入的命令,判断用户命令的合法性,举例来说:
这句 SQL 命令就不是一句合法的 SQL 命令,因为实际上不存在 FELECT 这一关键词
事实上,市面上的大部分数据库前端都会将用户输入的命令解析成抽象语法树 (AST) ,供后端处理,举例来说,下面是一颗解析 SQL 的 AST :
<select-statement>
├── <column-list>
│ └── <column-name>
│ └── name
├── <table-name>
│ └── students
└── <condition>
├── <expression>
│ ├── <MARK>
│ │ └── age
│ ├── <OP>
│ │ └── >
│ └── <CONST>
│ └── '18'
├── <logical-op>
│ └── AND
└── <expression>
├── <MARK>
│ └── gender
├── <OP>
│ └── =
└── <CONST>
└── 'M'3.2.2 数据库的后端
3.2.2.1 系统字典
数据库系统要对外维持自己的数据模型,就需要维护一些特定的信息。举例来说,如果是一个关系型的数据库,就需要维护自己目前库中有哪些表,表中有什么字段,哪些字段上存在索引这些信息。这一类的信息我们统称为数据库的多数据字典信息,属于是数据库系统自行维护的数据库元信息。数据库很大程度上需要依靠这些元信息来判断查询是否合法,以及如何执行查询。举例来说:当用户需要根据某一条件进行某一查询时,数据库需要根据元信息判断条件字段上是否存在索引,以此来决策具体的执行计划:
对于这句查询语句,数据库系统就需要根据元信息来查询这么几个点:
table1是否存在table1中有哪些字段table1的数据存储在哪里col1上是否有索引
3.2.2.2 查询计划器
查询计划器是所有数据库系统中最为复杂的部分,用于将逻辑上用户需要进行的查询计划转化为物理的执行计划,要明确到需要根据什么查数据,查什么数据,查到了数据之后进行怎么样的处理,具体的算子下沉还是上升等等问题,生成和优化物理执行计划本身是一个NP问题,这也是各个高性能数据库的技术核心。
在用户输入的命令被解析成 AST 并且通过数据字典的基本校验后,就进入到了查询计划器当中。
举例来说,考虑这么一条 SQL :
这里其实有三条明显的执行路径:
直接扫描全部数据,然后根据条件筛选
根据索引拉出所有
col1 >= 10的数据,然后筛选满足col2 <= 10的根据索引拉出所有
col2<=10的数据,然后筛选满足col1>=10的
哪个执行方案才是更优的呢?这就需要一些额外的信息辅助判断了:
例如,如果我们知道 col1>=10 的数据只有大概 10 条,而 col2<=10 的数据有 100000 条,那么显然第二个执行计划是更好的
反之,如果我们知道 col2<=10 的数据明显少于 col1>=10 的,那么显然第三个执行计划成本就更低
当然,如果说 col1 、col2 上不存在索引,或者说表的数据量很小,由于 id 在我们的数据库里是聚簇索引,不需要回盘查第二次,那可能直接拉所有的数据是更好的
3.2.2.3 事务管理器、锁管理器、并发控制器
这一部分,主要是大部分数据库都保有的、为了维持系统正确性、提供并发安全等而提供的机制,如果你的数据库要支持一些并发和隔离特性,那么需要一些额外的组件来支持数据库的正常工作。
这部分是一个比较复杂的问题,举例来说,对于以下2个同时执行的事务:
SELECT * FROM table1 WHERE col1 = 10 FOR UPDATE
SELECT * FROM table1 WHERE col2 = 10 FOR UPDATE
SELECT * FROM table1 WHERE col1 = 10 FOR UPDATE
SELECT * FROM table1 WHERE col2 = 10 FOR UPDATE这 2 个事务就会出现互相等待对方释放锁的情况,进而造成死锁,这是不可接受的情况,需要有一个事务主动回滚,才能解决这一问题。
同样地,一些复杂的并发场景需要数据库系统主动识别才能避免问题发生,例如:
SELECT id FROM table1 WHERE col1 = 10; -- 事务1,结果id=10
UPDATE table1 SET col1 = col1 + 10 WHERE col1 = 10; -- 事务2,提交
UPDATE table1 SET col1 = (10) + 10 WHERE id = 10; -- 事务1,提交上述的问题就是一个明显的并发问题,事务1读取并使用过期的值来对数据进行更新。
由于这部分的内容相对比较复杂,要系统性的描述需要比较大的篇幅,在之后的内容中会进一步进行讨论。目前仅仅讨论到存在的问题和需要引入解决这些问题的组件。
3.2.2.4 缓存池
当执行计划被确定之后,就会对硬盘进行大量的 io操作 ,理论上,这些 io操作 很可能是随机的,至少也是随机混合的,这一类的读写模式对硬盘不友好,而实际上,即使这种模式对硬盘是友好的,硬盘的数据读取时间对于 CPU 来说也是十分漫长的。
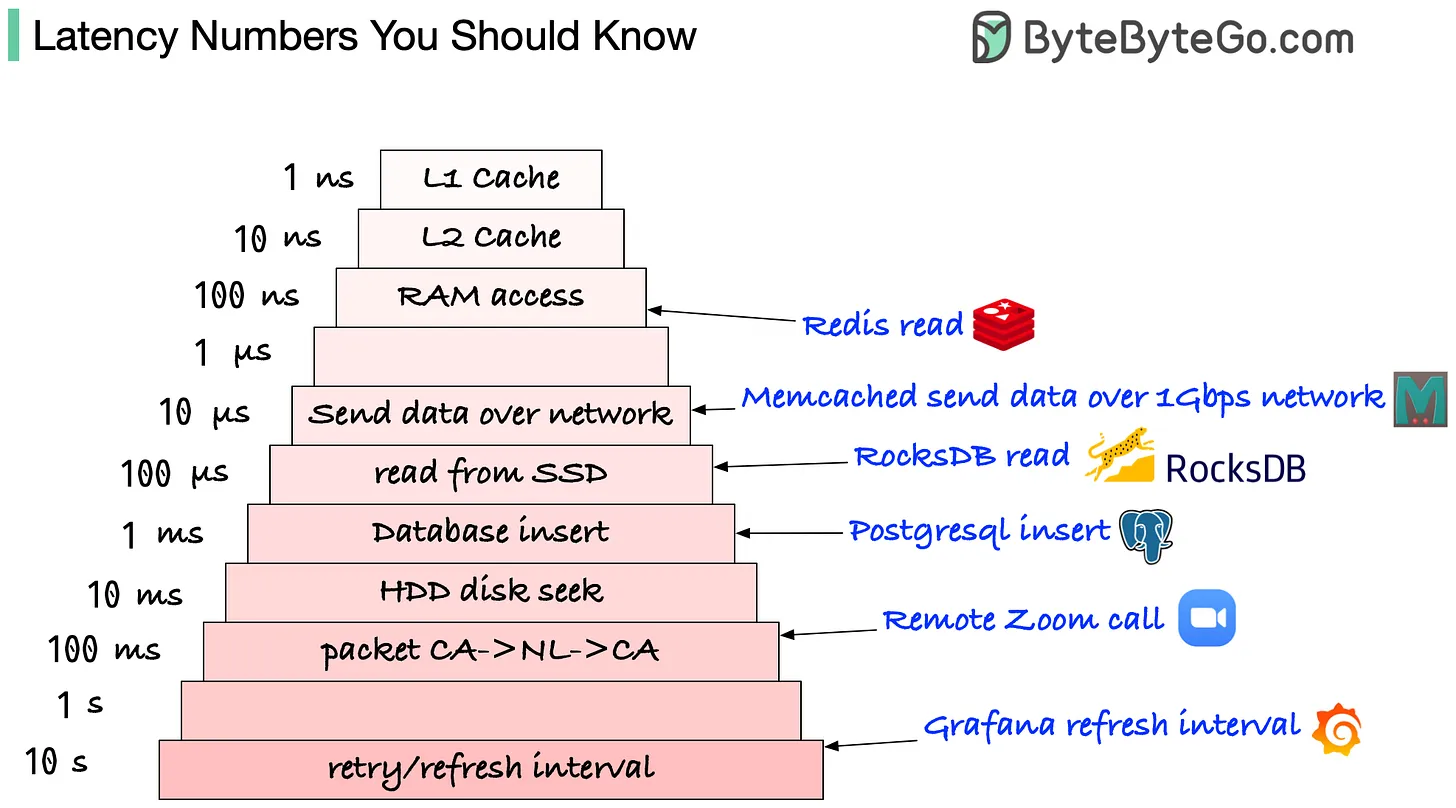
图 3.1: 各种介质的延迟
图源 https://blog.bytebytego.com/p/ep22-latency-numbers-you-should-know
因此,所有的io操作最好是在内存中进行,由缓存池负责对硬盘的实际io读写调度