第 2 章 问题引入
2.1 构建一个员工信息管理系统
在动手设计实现数据库之前,不妨先花一点时间头脑风暴一下数据库是什么。
其实,大部分的程序员在编写应用程序的时候,都不会意识到数据库承担了多少工作,这恰恰说明了数据库概念的成功,将数据存储、并发控制、一致性保证等功能从应用中切分出来,并且运用“事务”等概念来实现存储层功能的接口化,是一项了不起的工作。
为了更好地帮助读者认识到数据库的概念,我先从尝试着在不使用数据库的情况下实现一个员工信息管理系统开始,请读者和我一起思考,我们一起分析可能遇到的问题,并且思考数据库是如何解决它们的。
系统支持的功能
我们的信息管理系统要支持以下功能:
我们要可以插入新的员工信息到系统中,方便为新员工注册信息
我们要可以使用员工姓名查询员工信息,这样公司内的人能够通过姓名查询到他人的信息
为了存储信息,我们可以使用操作系统和文件系统提供的基本文件操作功能,可以在文件系统中创建空白文件,可以向文件中添加信息,也可以从任意位置读取文件。
系统的简易实现
有了上面这些条件,我可以给出一个比较简单的“员工信息管理系统”实现:
在这个实现中,我给每一条记录开启一个新的行,每一行中存储对应的员工信息,
每个员工信息的属性称为一列,每一行含有多个列,分别为员工信息的不同属性
在插入用户信息时,我保证写入的数据都符合这个格式
在查找用户信息时,我根据预先约定好的数据格式去解析数据文件,获取记录的雇员姓名,并返回所有符合要求的记录。
在具体实现上,为了遵循这一协议约定,我使用空文件来存储信息,在行与行之间使用 \n 分割,同一行的列之间使用 <SEP> 分隔。
下面是一个简单的实现版本:
import io
class EmployeeManager:
def __init__(self):
self.DBFILE = "employees.txt"
self.db = open(self.DBFILE, "a+", encoding='utf-8')
self.SEP = "<SEP>"
def write(self, name, phone, age)
self.db.seek(0, io.SEEK_END)
self.db.write("{0}{1}{2}{3}{4}{5}\n".format(name, self.SEP,
phone, self.SEP,
age, self.SEP))
self.db.flush()
def findByName(self, name):
self.db.seek(0)
for line in self.db.readlines():
line = line.strip()
line = line.split(self.SEP)
if line[0] == name:
self.db.seek(0)
return line
self.db.seek(0)
return None
if __name__ == '__main__':
emp = EmployeeManager()
emp.write("Tom", "+8613042552664", 32)
emp.write("Marry", "+8613142357624", 29)
# Try to find Tom
tom = emp.findByName("Tom")
if tom:
print("Tom exists")
jack = emp.findByName("Jack")
if jack:
print("Jack exists")
emp.write("Jack", "+8613051531", 34)最后,我们用一幅图来总结说明刚才我们所做的设计。用两个视图来概括,在文件的物理视图中,我们的文件如右图所示,而在程序和协议中,我们的数据表如左图所示。
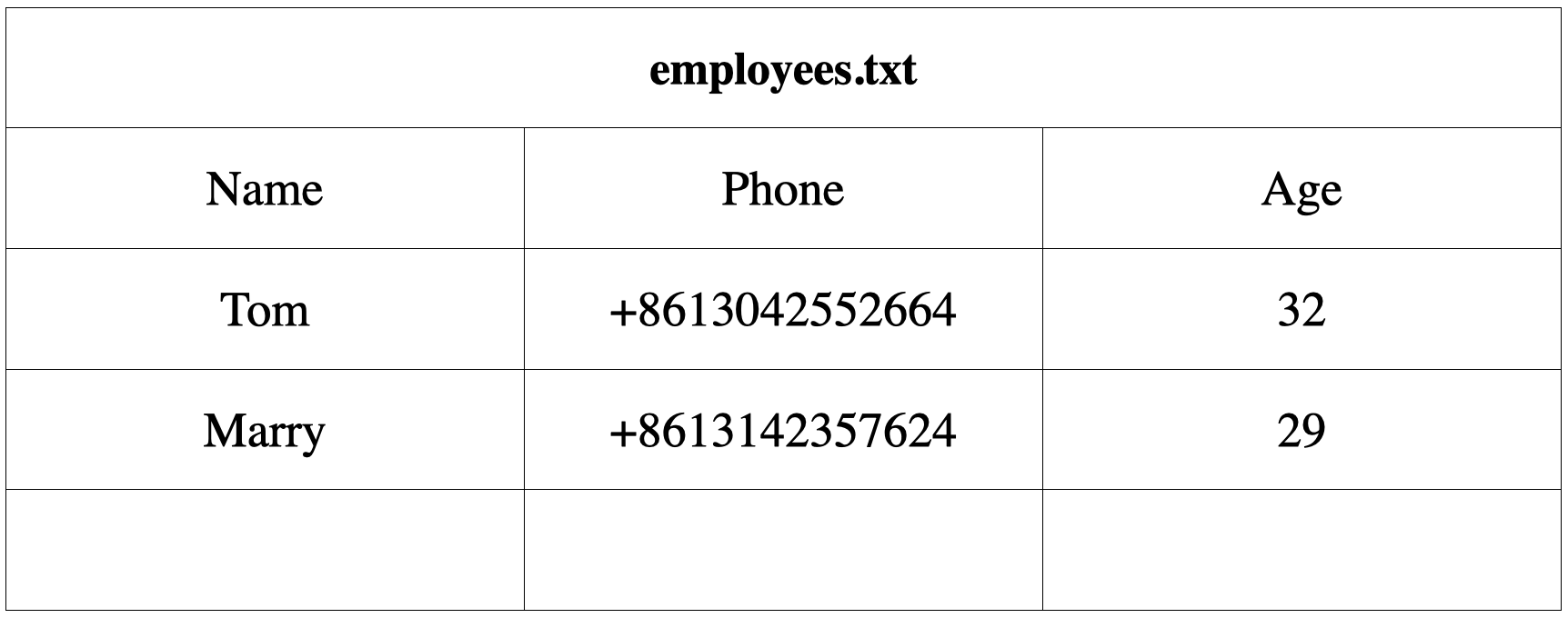
图 2.1: 雇员文件逻辑视图
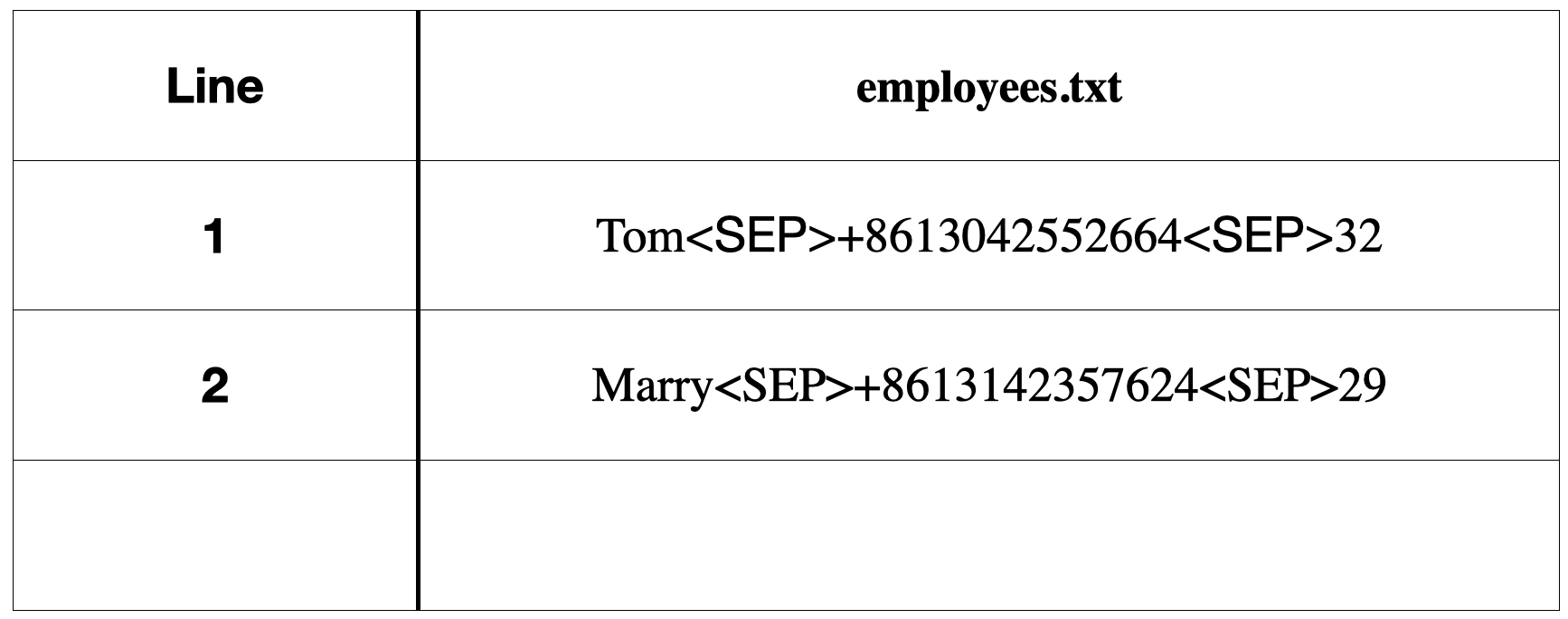
图 2.2: 雇员文件物理视图
2.2 员工信息管理系统的问题
在前文,我们一起实现了一个简单的员工信息管理系统。尽管这个数据库能够满足基本的功能需求,但它不可否认地存在一些缺陷。
在本文中,我会罗列这个信息管理系统可能出现的一些问题,并通过将这些问题分类,来识别数据库系统所做的工作、提供的保证:
与物理存储结构绑定的查询和写入逻辑
没有一种通用的查询语言,每个查找需求都需要编写单独的查找方法
findByName方法、write方法都直接与底层的数据存储方式耦合,查找数据的逻辑竟然需要精确到读取第几个字段,这是一种命令式 (imperative) 的做法,与目前的 SQL 语言的声明式查询是相对的,命令式的查询语言将底层实现暴露给最终用户,使得查询语言与底层实现耦合,这在日后是维护的噩梦
缺乏并发控制,读写操作互相排斥
数据库在写入的时候缺乏并发控制,可能出现两个进程同时写入一个文件的情况,造成文件损坏
findByName方法同样不是并发安全的,可能在一个进程读取文件时另一个进程将文件rewind由于直接依赖底层文件的指针位置,读写无法同时进行